
CachyOSでローカルLLM!Ollama + AlpacaでAIと会話する
Arch Linux系のCachyOSでローカルLLMが使える環境づくりをしてみる。
結論としては、OllamaとAlpacaをインストールした。
Ollamaのインストール
OllamaはローカルでLLMを使うにあたって、いい選択肢の1つだろう。
LM Studioもいいんだけど、CachyOSで使うならOllamaの方が便利かな、と思う。ちょっと前までLM StudioはAURでインストールできたんだけど、新しいバージョンになってAURではインストールできなくなってしまった。今では公式サイトからAppImageになっているパッケージをダウンロードして使うようだ。
一方で、Ollamaならpacmanですんなり入る。じゃあそれでやってみようって寸法だ。
私のデスクトップは、GPUがAMD Radeon RX 7600XTなので、rocmに対応したollamaをインストールした。
sudo pacman -S ollama-rocmGPUがNVIDIAなら ollama-cuda がいいんだろうし、もしかしたら ollama-vulkan も案外いけるかもしれない。この辺は環境に合わせて入れればいいようだ。
インストールはすんなり終わり。あとはコマンドでAIと会話できるようになる。
ollama run gemma4:e4b最近、Gemma4が出たので、これを使ってみたかったのだ。
コマンドを実行するとダイアログ形式 (インタラクティブモードとでもいうのかな)でやり取りできることが確認できた。
なお、gemma4はデフォルトだとthinkモードのようなので、応答が遅いようならthinkモードを切った方がよいかもしれない。thinkモードは起動時にOFFにすることもできるし、インタラクティブモードでOFFにすることもできる。
#起動時にthinkモードを切っておく
ollama run gemma4:e4b --think=false
または
#インタラクティブモードでthinkモードを切る
>>> /set nothink AIと会話できることを確認したら、Ctrl + Dでインタラクティブモードを抜け出し、次のコマンドでLLMを読み込んだメモリを解放してやる。
ollama stop gemma4:e4bOllamaをリモートで使えるようにする
普通にコンソールで使うならここまでで十分なんだけど、ollamaをサービスとして起動するようにしておくことにした。というのも、我が家の場合、このデスクトップが一番強力なマシンなので、他のPCからこのデスクトップの火力を使えるようにしておくと何かと便利かも?と思い。
sudo systemctl enable ollama.service
sudo systemctl start ollama.service実際は、リモートPCから使えるようにするには、他にいくつかの設定が必要になる。詳しくは公式サイトを参考にしてもらえばよいが、こんな設定をしている。
まずは、/usr/lib/systemd/system/ollama.service に以下を追記する。
[Service]
Environment="OLLAMA_HOST=0.0.0.0:11434"この設定を入れておくことで、リモートPCからollamaに接続できるようになる。
その上で、リモートPCからこのデスクトップのollamaサービスに接続できるように、ファイアウォールのポートを解放しておく必要がある。我が家の環境で、ひとまずローカルLANから接続できるようにしておいた。
sudo ufw allow from ローカルLAN/セグメント to any port 11434 proto tcp同じLAN内にあるサーバー上に構築しているdifyから呼ぶことができたし、これでちょっとしたAIサービスを作ろうと思ったら作れそうな予感がしている。
AlpacaをインストールしてOllamaをGUIで使えるようにする
Ollamaは最近、デスクトップアプリが同梱されるようになったのだが、WindowsやMacにしか対応しておらず、Linuxでは使えない。
そこで、その他のOllamaフロントエンドを探してインストールすることにした。
いくつか候補があった中で、Alpacaを使ってみることにする。
AlpacaはAURからインストールすることができるみたいなんだけど、なぜかすんなりインストールできなかった。あんまり悩むのも面倒だから、Flatpakでも提供されているみたいだし、そちらからインストールしてやる。
FlatpakをCachyOSで使えるように設定してやって・・・

FlatpakからAlpacaをインストールする。今度はすんなり入った。
起動すると、アルパカっぽいのが出てきた。ラマ (ollama)に対してアルパカか。どうもラマとアルパカは祖先が同じで、いずれもラクダ科の動物だそうだから、そのつながりでollamaに対してalpacaにしたのかな。
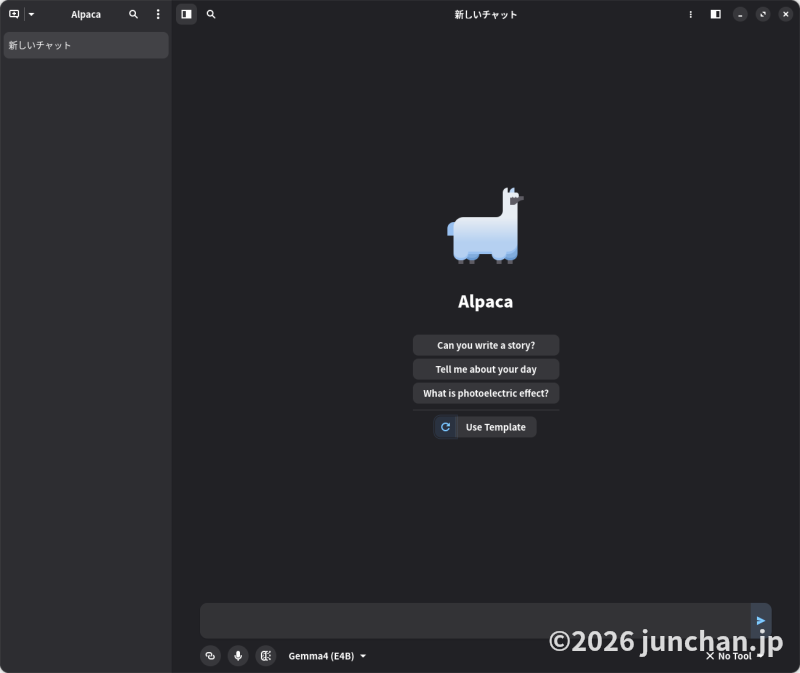
Alpacaにはモデルの管理をする画面もあり、ここからLLMをインストールすることもできる。画面下の「Gemma4 (E4B)」と書かれているドロップダウンの左側にあるアイコンからモデル管理画面を呼び出す。
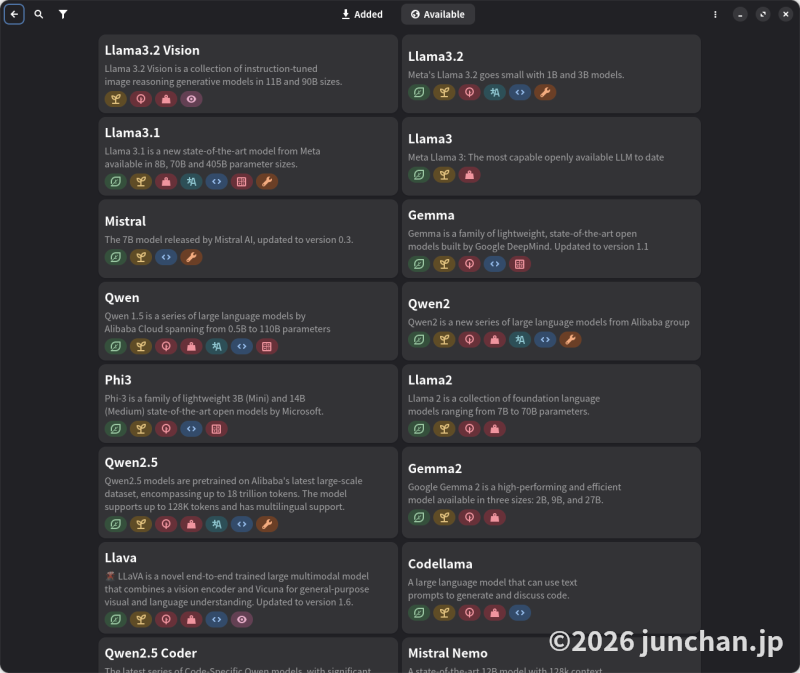
上部中央に「Added」と「Available」があり、Addedはインストール済のもの、Availableはインストール可能なものが表示される。ただ、Availableで表示されるリストは、最新のものではないようだ。
ちなみに、先にollamaコマンドでダウンロードしたモデルはAddedに収容されていて、すぐ使えるようになっていた。そのため、Availableにないものを使う場合は、ollamaコマンドでダウンロードしておくのがいいのだろう。
モデルを選んだら、あとは入力欄になんやかんやと打ち込んだらAIと会話できる。
なお、AlpacaからOllamaの呼び出しは悩まずにできたんだけど、はたしてAlpacaがOllamaサービスを呼んでいるのか、Alpacaが直接Ollamaを動かしているのかはよくわかっていない。まあ、どっちでもいいやと思っているので検証もしていない。多分、OllamaをインストールしてからAlpacaをインストールしたので、よろしく設定してくれたのだろう。
いずれにせよ、GUIでローカルLLMとチャットできるようになったことが重要なのだ。
新しいチャットを作ったり、使うモデルを切り替えたりするといった作業が一通りGUIでできるようになったことで、Ollamaが格段に使いやすくなった。Alpacaには他にも機能があるみたいだし (他のAIサービスに接続するとか)、使いながら開拓するかな。
あと、AlpacaからOllamaのthinkモードをOFFにするには、インタラクティブモードのときと同じように、普通にチャットから /set nothink と打ち込んでやればOKだった。
おわりに
CachyOSでローカルLLMを使おうと思い、環境を整備した。
Ollama + Alpacaをインストールすることで、GUIからローカルLLMのAIとチャットできるようになった。
ひとまず使えることが確認できたので、他にどんなことができるかは追って検証してみよう。特にAlpacaは別にOllama専用のフロントエンドというわけでもなさそうだから、色々やれることはあるんだろう。
便利に使ってやりたい。