
動画ファイルから要約テキストを作成するフローをCachyOSのマシンで作ってみた (ffmpeg + whisper.cpp + ollama)
生成AIを使って、手持ちの動画ファイルから、動画の内容を要約してもらうことにした。
経緯 – 動画ファイルを探すのが手間だった
私の放送大学体験談をYouTubeチャンネルで公開しているんだけど、週1くらいで数年投稿してきたら、結構な量になっている。
手持ちの動画ファイルの中から、欲しいファイルを探すのはなかなか難しい。というか手間だ。いちいち動画ファイルの再生なんてしたくない。
そこで、要約テキストを作ってまとめておけば、そのテキストを検索すればさくっと見つけられるようになるんじゃないかと思ったのだ。
あるいは、要約テキストをまとめておけば、前にこのネタやったなとか、そろそろこのネタやる時期かな、なんて考えるきっかけにもなりそう。
そんなことを考えながら、過去に撮影して編集した動画から、要約テキストを作ることにしたのだった。
動画ファイルから要約テキストを出力するまでのフロー
動画ファイルから要約テキストを作るにあたって、やり方はいくつかあるんだけど、私は以下のフローでやってみることにした。
- 動画ファイルから音声ファイルを抜き出す
- 音声ファイルから文字起こしして、テキストファイルにする
- 文字起こししたテキストファイルを生成AIに読み込ませて、要約してもらう
使用するパソコンは、我が家で最も高性能なデスクトップパソコン。OSはCachyOS (Arch Linux系)で、GPUにAMD Radeon RX 7600XTを使っている。まあまあなスペックのパソコンだろう。

それぞれの工程で、以下のアプリを使っていく。
- 動画ファイルから音声ファイルを抜き出す → ffmpeg
- 音声ファイルから文字起こしして、テキストファイルにする → whisper.cpp
- 文字起こししたテキストファイルを生成AIに読み込ませて、要約してもらう → ollama
ffmpegは pacman ですぐインストールできるし、ollamaは前にインストールしている。
よって、whisper.cpp をインストールしてやる必要があった。
whisper.cppをインストール
whisper.cpp は、ChatGPTで一躍有名になったOpenAI社が作成した音声認識アプリ「whisper」をC++で実装したものだそうだ。まあ、細かいことは割愛。この whisper.cpp は高精度な音声認識ができるものだということがわかってもらえれていればいい。

whisper.cpp を使うには、ソースコードをダウンロードしてきて、ビルドしてやる必要がある。となると、ディレクトリ構成を整理しておかないと再現性のある操作ができない。
ということで、今回、動画ファイルから要約テキストを作成するにあたって、以下のようなディレクトリ構成にしている。
movie-summary
+ whisper.cpp
+ movie.mp4 (要約テキストを作るための動画ファイル)
+ voice.wav (ffmpegで作る)
+ voice.txt (whisper.cppで作る)whisper.cppのダウンロードからビルドに関しては、公式ページに準じて行ったので、そちらも参考にしてほしい。
まず、movie-summary ディレクトリに移動して、whisper.cpp をGithubからダウンロードしてくる。
cd movie-summary
git clone https://github.com/ggml-org/whisper.cpp.gitしばらく待つとソースコードのダウンロードが終わる。ダウンロードが終わったら、新しくできた whisper.cpp ディレクトリに移動する。
cd whisper.cppwhisper.cpp に移動したら、音声認識に使うモデルのダウンロードをする。モデルはいくつもあるのだが、我が家のデスクトップであれば一番大きいモデルでも大丈夫なようなので、large-v3 を使うことにした。きっと大きいものほど認識力が高いのだろう。
sh ./models/download-ggml-model.sh large-v3このモデルは3GBくらいあったので、ダウンロードにはそれなりに時間がかかった。
続いて、whisper.cppをビルドする。
cmake -B build -DGGML_HIP=ON
cmake --build build -j --config ReleaseAMDのGPUに対応させたかったので、-DGGML_HIP=ON というオプションをつけている。公式ページにはこんなオプションは書いてないが、これをつけることでAMDのGPUに対応したビルドが作れるらしい。
ビルドに問題がなければ、音声認識をする準備は整ったことになる。
これで今回使うすべてのアプリが揃ったので、動画ファイルから要約ファイルを作っていく。
動画ファイルから音声ファイルを抜き出す
まず、動画ファイルから音声ファイルを抜き出すには、ffmpeg を使う。老舗アプリだな。
whisper.cpp をビルドするにあたって whisper.cpp ディレクトリに移動しているので、そこでffmpegを実行するなら、ファイルパスに気をつけてやる必要がある。以降、whisper.cpp ディレクトリで作業するようコマンドは書いていく。
ffmpeg -i ../movie.mp4 -ar 16000 -ac 1 -c:a pcm_s16le ../voice.wavほとんど一瞬で動画ファイルから音声ファイルを抜き出すことができた。
音声ファイルから文字起こしして、テキストファイルにする
音声ファイルができたら、先ほどビルドした whisper.cpp を使って文字起こしをしよう。
./build/bin/whisper-cli -m ./models/ggml-large-v3.bin ../voice.wav -l ja -otxt -of ../voice主なオプションは以下のとおり。
- -m モデルを指定する
- -l ja 日本語の音声ファイルのつもりで読み取るよう指示する
- -otxt テキスト形式で出力するよう指示する
- -of 出力ファイル名 (拡張子はwhisper.cppがつけるので不要)
音声ファイルを文字起こししている間は、コンソールに途中経過が出ているので、ぼーっと眺めておく。漢字が違うとか、単語が違うとかは結構あるのがわかる。
ただ、このあとどうせ生成AIにかけて要約するので、細かいことは気にしない。
気になるようであれば、出力されたファイル voice.txt を手直しするのもいいだろう。
文字起こししたテキストファイルを生成AIに読み込ませて、要約してもらう
文字起こししたテキストファイルができたら、生成AIに読みこませて要約してもらう。ここではLLMにgemma4:e4b を指定している。
ollama run gemma4:e4b "以下の文字起こしデータを、重要なポイント3つの箇条書きと、最後の結論1行で分かりやすく要約してください: $(cat ../voice.txt)"ollamaがごちゃごちゃとコンソールにアウトプットしていくのを眺めよう。
なお、gemma4:e4bはデフォルトでは思考モードで走るので、最初の方はその思考モードの内容が出力される。最後の方にまとめてくれるのが今回欲しい要約テキストだ。markdown形式で出力される。
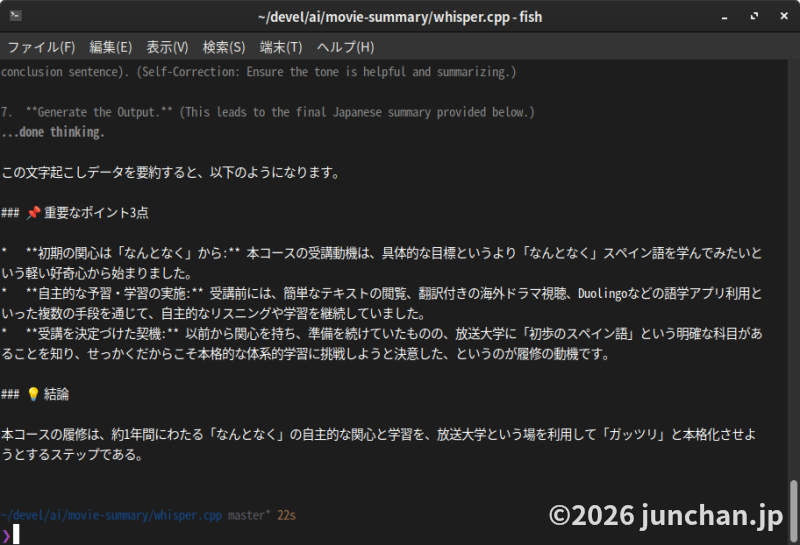
ollamaを実行するところでテキストファイルに出力してやってもよいのだが、普通にリダイレクトしても改行コードがおかしくなったりしたので、ひとまずコンソールに出力するところまでとした。
コンソールに出力された要約をテキストファイルにコピペしておしまいだ。
要約テキストの確認
ここでサンプルを示す。もとの動画はこちら。
最終的に出力された要約はこちら。
### 📌 重要なポイント3点
* **初期の関心は「なんとなく」から:** 本コースの受講動機は、具体的な目標というより「なんとなく」スペイン語を学んでみたいという軽い好奇心から始まりました。
* **自主的な予習・学習の実施:** 受講前には、簡単なテキストの閲覧、翻訳付きの海外ドラマ視聴、Duolingoなどの語学アプリ利用といった複数の手段を通じて、自主的なリスニングや学習を継続していました。
* **受講を決定づけた契機:** 以前から関心を持ち、準備を続けていたものの、放送大学に「初歩のスペイン語」という明確な科目があることを知り、せっかくだからこそ本格的な体系的学習に挑戦しようと決意した、というのが履修の動機です。
### 💡 結論
本コースの履修は、約1年間にわたる「なんとなく」の自主的な関心と学習を、放送大学という場を利用して「ガッツリ」と本格化させようとするステップである。大体いい感じに要約されていると思う。
おわりに
動画ファイルをざっと見返すために、要約テキストを作成する仕組みづくりをしてみた。
今回採用した whisper.cpp はかなり高精度な音声認識アプリで、音声ファイルからいい具合に日本語文章を起こしてくれた。
こういう仕組みがあっさりデスクトップで作れるなんて、本当に便利な時代である。
動画ファイルから要約テキストを作る流れはできたので、今度は複数ファイルを一気に実行できるようなバッチを作ってみるかな。あるいは、n8nなどを使って、動画ファイルを配置したら自動的に要約テキストを作るような仕組みを作るのも面白いかもしれない。
ひとまず、今回やりたいことは実現できたのでこれで良しとしよう。